La lettre hebdomadaire de Café IA |
| |
|
Bonjour à tous.tes,
Nous sommes le vendredi 30 janvier 2026. Bienvenue dans la lettre d’information de Café IA. Au menu de cette semaine : on continue notre série sur les imaginaires de l’IA en nous intéressant aux mythes de l’IA ✦ La ressource de la semaine : où se former à l’IA ? ✦ Et comme chaque semaine, retrouvez toute l’actualité de la communauté Café IA… Bonne lecture ! |
Les discours autour de l’IA produisent et résultent des mythes qui influencent notre compréhension de ce qu’elle est, produisant une perception confuse de sa réalité… pour mieux influer sur les transformations légales à venir.
La technologie ne produit pas que des solutions, elle produit aussi beaucoup de promesses, d’imaginaires, d’idéologies et de mythes. Derrière le marketing des produits et des services, les entreprises déploient des métaphores simples et convaincantes qui réduisent la complexité des transformations à l’œuvre. « Ils pollinisent l’imagination sociale avec des métaphores qui mènent à des conclusions, et ces conclusions façonnent une compréhension collective » plus ou moins fidèle à la réalité. Les discours sur l’IA générative reposent sur de nombreux mythes et promesses, explique Eryk Salvaggio qui tente d’en dresser la liste [1]. Ces promesses produisent souvent une compréhension erronée du fonctionnement de l’IA et induisent en erreur ceux qui veulent les utiliser.
Il y a d’abord les mythes du contrôle qui visent à nous faire croire que ces systèmes sont plus fiables qu’ils ne sont. Parmi les mythes du contrôle, il y a celui de la productivité, qui nous répète que ces systèmes nous font gagner du temps, nous font produire plus rapidement. « Le mythe de la productivité suggère que tout ce à quoi nous passons du temps peut être automatisé ». L’écriture se réduit à un moyen pour remplir une page plutôt qu’un processus de réflexion [2]. Le mythe du prompt suggère que nous aurions un contrôle important sur ces systèmes, nous faisant oublier que très souvent, nos mots mêmes sont modifiés avant d’atteindre le modèle, via des filtres qui vont modifier nos invites elles-mêmes [3]. D’où l’incessant travail à les peaufiner pour améliorer le résultat. « Le mythe de l’invite permet de masquer le contrôle que le système exerce sur l’utilisateur en suggérant que l’utilisateur contrôle le système ».
Outre le mythe du contrôle, on trouve également le mythe de l’intelligence. Le mythe de l’intelligence confond le fait que le développement des systèmes d’IA aient été inspirés par des idées sur le fonctionnement de la pensée [4] avec la capacité à penser. On nous répète que ces systèmes pensent, raisonnent, sont intelligents… suggérant également qu’ils devraient être libres d’apprendre comme nous le sommes, pour mieux faire oublier que leur apprentissage repose sur un vol massif de données [5] que sur une capacité à apprendre. Parmi les mythes de l’intelligence, on trouve donc d’abord le mythe de l’apprentissage. Mais cette métaphore de l’apprentissage elle aussi nous induit en erreur. Ces modèles n’apprennent pas. Ils sont surtout le produit de l’analyse de données. Un modèle n’évolue pas par sélection naturelle : il est optimisé pour un ensemble de conditions dans lesquelles des motifs spécifiques sont renforcés. Ce n’est pas l’IA qui collecte des données pour en tirer des enseignements, mais les entreprises qui collectent des données puis optimisent des modèles pour produire des représentations de ces données à des fins lucratives. Le mythe de l’apprentissage vise à produire une équivalence entre les systèmes informatiques et la façon dont nous mêmes apprenons, alors que les deux sont profondément différents et n’ont pas la même portée ni la même valeur sociale. Le mythe de l’apprentissage permet surtout de minimiser la valeur des données sans lesquelles ces systèmes n’existent pas.
Le mythe de la créativité fait lui aussi partie du mythe de l’intelligence. Il entretient une confusion entre le processus créatif et les résultats créatifs. Si les artistes peuvent être créatifs avec des produits d’IA, les systèmes d’IA génératifs, eux, ne sont pas créatifs : ils ne peuvent pas s’écarter des processus qui leur sont assignés, hormis collision accidentelles. Le mythe de la créativité de l’IA la redéfinit comme un processus strict qui relèverait d’une série d’étapes, une méthode de production. Il confond le processus de créativité avec le produit de la créativité. Et là encore, cette confusion permet de suggérer que le modèle devrait avoir des droits similaires à ceux des humains au prétexte de sa créativité.
Salvaggio distingue une troisième classe de mythes : les mythes futuristes qui visent à produire un agenda d’innovation. Ils spéculent sur l’avenir pour mieux invisibiliser les défis du présent, en affirmant continûment que les problèmes seront résolus. Dans ces mythes du futur, il y a d’abord le mythe du passage à l’échelle ou de l’évolutivité : les problèmes de l’IA seront améliorés avec plus de données. Mais ce n’est pas en accumulant plus de données biaisées que nous produirons moins de résultats biaisés. L’augmentation des données permet surtout des améliorations incrémentales et limitées, bien loin de la promesse d’une quelconque intelligence générale. Aujourd’hui, les avantages semblent aller surtout vers des modèles plus petits mais reposant sur des données plus organisées et mieux préparées. Le mythe de l’évolutivité a lui aussi pour fonction d’agir sur le marché, il permet de suggérer que pour s’accomplir, l’IA ne doit pas être entravée dans sa course aux données. Il permet de mobiliser les financements comme les ressources… sans limites. Oubliant que plus les systèmes seront volumineux, plus ils seront opaques et pourront échapper aux réglementations.
Un autre mythe du futur est le mythe du comportement émergent [6]. Mais qu’est-ce qui conduit à un comportement émergent ? « Est-ce la collecte de grandes quantités d’écrits qui conduit à une surperintelligence ? Ou est-ce plutôt la conséquence de la précipitation à intégrer divers systèmes d’IA dans des tâches de prise de décision pour lesquelles ils ne sont pas adaptés ? » Les risques de l’IA ne reposent pas sur le fait qu’elles deviennent des machines pensantes, mais peut-être bien plus sur le fait qu’elles deviennent des machines agissantes, dans des chaînes de décisions défaillantes.
Salvaggio plaide pour que nous remettions en question ces mythes. « Nous devons travailler ensemble pour créer une compréhension plus rigoureuse de ce que ces technologies font (et ne font pas) plutôt que d’élaborer des déclarations de valeur (et des lois) qui adhèrent aux fictions des entreprises ».
C’est peut-être oublier un peu rapidement la valeur des mythes et des promesses technologiques. Les mythes de l’IA visent à produire non seulement une perception confuse de leur réalité, mais à influer sur les transformations légales. Les promesses et les mythes participent d’un narratif pour faire évoluer le droit en imposant un récit qui légitime le pouvoir perturbateur de la technologie. Les mythes permettent de crédibiliser les technologies, expliquait déjà le chercheur Marc Audetat dans l’excellent livre collectif Sciences et technologies émergentes : pourquoi tant de promesses ? [7]. Comme le disait l’ingénieur Pierre-Benoît Joly dans ces pages, « les promesses technoscientifiques ont pour fonction de créer un état de nécessité qui permet de cacher des intérêts particuliers ». Les mythes et les croyances de l’IA ont d’abord et avant tout pour fonction de produire le pouvoir de l’IA et de ceux qui la déploient.
|
De quelle boîte noire l’IA est-elle la boîte ? |
Qu’y a-t-il dans la boîte noire de l’IA ? Derrière l’opacité technique, la complexité n’est-elle pas d’abord un prétexte pour dissimuler la redevabilité que devraient nous proposer ces outils ?
Le fonctionnement des modèles d’IA est souvent comparée à une boîte noire, c’est-à-dire à des structures foncièrement inintelligibles, intrinsèquement opaques, dont l’extrême complexité technique et l’intrication des systèmes entre eux empêcherait la compréhension même. Les boîtes noires désignent les programmes dont le fonctionnement, l’architecture, ne peut pas être connu du fait de leur complexité ou de leur fermeture, mais dont on peut tenter de comprendre le fonctionnement en fonction des valeurs de sorties (et parfois d’entrées, quand elles sont disponibles) [8]. Le problème de la boîte noire n’est pourtant pas qu’un problème de compréhension, de complexité et d’opacité technique. Il traduit également l’enjeu de concentration de pouvoir qui obscurcit la façon même dont les décisions sont prises dans les systèmes socio-techniques [9]. Ce que masque le terme de boîte noire, ce ne sont pas des algorithmes opaques, mais des choix de conception : des décisions conscientes quant aux objectifs à privilégier, aux sources de données à utiliser et aux mesures de sécurité à mettre en place.
Si l’opacité technique intrinsèque de l’IA, la manière dont elle fonctionne, est de plus en plus éclairée par la science [10], la volumétrie des paramètres que l’intelligence artificielle actionne rend notre compréhension de son fonctionnement parcellaire. L’opacité de l’IA reste liée à sa complexité technique.
« La boîte noire de l’IA ne renvoie pas aux mystères d'un raisonnement moral interne, mais à l'immense échelle et à la complexité de l'attribution des poids dans le modèle », rappelait avec pertinence Eryk Salvaggio [11]. Les grands modèles de langage associent des mots dans un vaste espace vectoriel pour rapprocher les mots entre eux. Ce qui reste en partie obscur, c'est la manière dont les corrélations spécifiques sont inférées à partir d'immenses données d'entraînement.
Lors d’un entraînement de sécurité, Anthropic a soumis à Claude un scénario dans lequel Claude s’est mis à faire chanter un utilisateur pour éviter qu’il ne le débranche. La consigne ne laissait au modèle que deux options : le chantage ou l’acceptation de l’arrêt du système. Les réponses de Claude ont largement préféré le chantage. « Mais le modèle n'a pas “pris” cette décision par raisonnement éthique. Il a suivi des schémas statistiques façonnés par la consigne, le dirigeant vers des corrélations linguistiques », des proxies qui font venir avec eux leurs mondes, comme l’expliquait Frédéric Kaplan [12]. « Les LLM ne font pas de choix moralement éclairés. Ils imitent le langage en se basant sur des consignes, l'entraînement et l'apprentissage par renforcement. Soumettez un scénario au modèle, et il produira un langage cohérent avec ce scénario, tout comme s'il devait écrire une histoire », rappelle Salvaggio. L'expression « boîte noire » ne fait référence qu’à la difficulté de clarifier le flou mathématique qui sous-tend ces liens. « La boîte noire relève des statistiques, et non de l'éthique ».
Le terme de « boîte noire » véhicule une représentation erronée de ce que produisent les IA. La création de mythes est un aspect crucial de l'industrie de l'IA, et les boîtes noires sont intrinsèquement liées aux récits que cette industrie propage pour asseoir son pouvoir. Quand Dario Amodei, le PDG d’Anthropic, explique que les chercheurs en IA ne comprennent pas le fonctionnement de leurs propres créations, il explique qu’ils ne comprennent pas ce qui lie les représentations vectorielles entre elles et comment les ajuster. Un modèle d'IA n’est qu’un amas impénétrable de valeurs numériques [13], reliant des vecteurs regroupés de manière incompréhensible lors de la phase d'apprentissage. Il en résulte des modèles d'IA non modifiables. Si les ingénieurs pouvaient les modifier, ils auraient un meilleur contrôle sur leurs résultats. Mais parvenir à un tel contrôle soulève néanmoins d'énormes défis : il ne rendrait pas les modèles « précis ». Il s'agirait plutôt d'un meilleur contrôle de la définition de la précision. En attendant, il n'existe aucun contrôle précis sur ces connexions.
Mais « cela ne signifie pas pour autant que nous ignorons le fonctionnement de ces systèmes. Cette « intuition » du fonctionnement des choses érige la modélisation statistique en dogme. L'absence de preuves devient source de foi. L'absence de contrôle sur un système peut, pour certains, être perçue comme la preuve d'une intelligence divine : c'est le début du mythe ». Pour Salvaggio, le manque de contrôle rend la technologie médiocre, faillible. A mesure que les systèmes d’IA utilisent tous les mêmes données, les modèles se rapprochent au risque qu’ils produisent tous peu ou prou des réponses de plus en plus proches les uns des autres, une forme de vérité transcendante ou unique. Pourtant, chacun tente de se différencier par des formes de personnalisation qui ne sont pas toujours publiques et qui orientent les réponses des modèles, à l’image des instructions de sécurité de Grok. La boîte noire de l’IA, demain, pourrait bien plus reposer dans ces orientations données aux systèmes, dans les listes de contraintes cachées aux utilisateurs, dans les réglages de modération des systèmes [14] que dans la complexité des paramètres de ces systèmes statistiques.
Le mythe partagé autour de la « boîte noire » de l'IA entretient une confusion utile quant à ce qui peut et ne peut pas être connu. Il contribue à rendre ces systèmes plus mystérieux, voire plus sublimes, qu'ils ne le sont en réalité. Il alimente le mythe du risque existentiel [15].
Salvaggio rappelle que l'interprétabilité n'est pas synonyme de transparence.
La transparence implique de partager les instructions du système et les données utilisées pour l'apprentissage. Elle suppose également de publier les critères d'évaluation de ces données, ainsi que les modalités de modification du texte saisi par l'utilisateur avant ou après son affichage. L’interprétabilité, elle, consiste à mieux comprendre certains des mécanismes de fonctionnement de ces modèles et utiliser cette compréhension pour les améliorer. On sait par exemple que les modèles s’adaptent à ce qu’ils comprennent ou infèrent des utilisateurs, en évaluant selon les mots utilisés,leurs statuts socio-économiques, leurs niveaux d’éducation, leurs âges ou leurs genres. Pour comprendre que leurs réponses ne sont pas objectives, il faut pouvoir doter les utilisateurs d’une compréhension de la perception que ces outils ont d’eux. Par exemple, si vous demandez les options de transport entre Boston et Hawaï, les réponses peuvent varier selon la perception que le modèle a de votre statut socio-économique [16]. D’où l’enjeu, pour ouvrir les boîtes noires à également les rendre plus interprétables, c’est-à-dire à doter les chatbots d’outils permettant à l’utilisateur de comprendre comment il est calculé [17].
Pour Salvaggio, la transparence et l’interprétabilité ne consistent pas à connaître le fonctionnement de chaque neurone ou paramètre de l’IA. Par contre, elles devraient nous éclairer pour comprendre la fiabilité de l’IA et notamment nous aider à nous opposer au déploiement de l’IA là où la fiabilité est primordiale, là où la redevabilité et l’opposabilité sont essentielles [18]. |
Notes :
[1] Eryk Salvaggio, “Challenging the myths of generative AI”, Tech Policy Press, 29 août 2024 : https://www.techpolicy.press/challenging-the-myths-of-generative-ai/ Voir également la liste qu’en dresse Irénée Régnauld, “Huit mythes de l’intelligence artificielle pour déconstruire la Hype”, Maisouvaleweb.fr, 5 mars 2025 : https://maisouvaleweb.fr/huit-mythes-de-lintelligence-artificielle-pour-deconstruire-la-hype/ Ainsi que le livre de Arvind Narayanan et Sayash Kapoor, AI Snake Oil, Princeton University Press, 2024 et son compte-rendu in Hubert Guillaud, “Comprendre ce que l’IA sait faire et ce qu’elle ne peut pas faire“, Danslesalgorithmes.net, 10 octobre 2024 : https://danslesalgorithmes.net/2024/10/10/comprendre-ce-que-lia-sait-faire-et-ce-quelle-ne-peut-pas-faire/
[2] Hubert Guillaud, “ChatGPT : le mythe de la productivité”, Danslesalgorithmes.net, 17 septembre 2024 : https://danslesalgorithmes.net/2024/09/17/chatgpt-le-mythe-de-la-productivite/
[3] Eryk Salvaggio, “Shining a Light on “Shadow Prompting”, Tech Policy Press, 19 octobre 2023 : https://www.techpolicy.press/shining-a-light-on-shadow-prompting/ [4] Comme le raconte très bien Pablo Jensen, Deep earnings, le néolibéralisme au cœur des réseaux de neurones, C&F éditions, 2021.
[5] Faut-il le rappeler, sans la créativité des travailleurs qui produisent l'art, la science et le journalisme qui alimentent de leurs données les IA génératives, ces machines ne sauraient rien produire. Les contenus synthétiques sont tous basés sur ce que beaucoup dénoncent comme un vol de données et l'exploitation du travail d'autrui. C’est l’un des aspects du caractère extractiviste voire colonialiste de l’IA. Sur ces enjeux, voir par exemple Ulises A. Mejias et Nick Couldry, Data Grab : the new colonialism of Big Tech (and how to fight back) WH Allen, 2024.
[6] Pour le dire rapidement, le comportement émergent fait référence à un comportement complexe qui résulte de l’interaction de règles ou d’éléments simples, sans aucune programmation explicite pour le comportement résultant. Dit plus simplement encore, c’est la promesse que les systèmes statistiques de l’IA puissent devenir intelligents.
[7] Marc Audétat (dir.), Pourquoi tant de promesses ? Sciences et technologies émergentes, Hermann, 2015.
[8] Sur le sujet, voir Frank Pasquale, Black Box Society, FYP éditions, 2015. Si l’image de la boîte noire est couramment associée à la cybernétique de Norbert Wiener (1948), il faut rappeler qu’elle provient des théories comportementalistes et notamment des travaux des psychologues John Watson et Burrhus Frederic Skinner qui développent le « behaviorisme », une méthode permettant d’étudier les relations statistiques entre l’environnement et le comportement. Cf. Anthony Masure, “Résister aux boîtes noires. Design et intelligence artificielle”, décembre 2019 : https://www.anthonymasure.com/articles/2019-12-resister-boites-noires-design-intelligences-artificielles. Voir aussi Tyler Reigeluth, “Boîte noire”, in Thierry Ménissier (dir.), Vocabulaire critique de l’intelligence artificielle, Hermann, 2025.
[9] Virginia Dignum, The AI paradox, How to make sense of a complex future, Princeton University Press, 2026.
[10] Nicolas Six, “Les IA, des « boîtes noires » dont les chercheurs tentent de déchiffrer le fonctionnement”, Le Monde, 30 juillet 2025 : https://www.lemonde.fr/pixels/article/2025/07/30/les-ia-des-boites-noires-dont-les-chercheurs-tentent-de-dechiffrer-le-fonctionnement_6625410_4408996.html
[11] Eryk Salvaggio, “The Black Box Myth: What the Industry Pretends Not to Know About AI”, Tech Policy Press, 17 juin 2025 : https://www.techpolicy.press/the-black-box-myth-what-the-industry-pretends-not-to-know-about-ai/
[12] Frédéric Kaplan, “Proxies”, in “Espèces d’IA”, revue Terrain n°82, printemps 2025 : http://www.revueterrain.fr Comme nous le disions précédemment - https://hubtr.bonjour.cafeia.org/mirror201/2342/4408?k=b5932ec08e5c81269c1d10e7e18ed3ef “Kaplan rappelle combien les mots que nous utilisons dans les requêtes avec lesquelles nous interrogeons les modèles d’IA générative font surgir des mondes. Certains agissent comme des proxies pour contrôler la trajectoire des réponses. Ces mots agissent comme des « représentations compressées » et sont à la fois, des intermédiaires et des intégrateurs statistiques, qui convoquent des univers de mots associés. Kaplan exemplifie son propos en convoquant d’un mot des représentations. Il prend l’exemple de James Bond qui permet de faire sortir les réponses d’un chatbot de leur bassin d’attraction, de les réorienter en évoquant un trope narratif plus puissant. Un LLM ne veut pas vous donner la recette d’une bombe artisanale, il suffit de convoquer James Bond pour qu’il vous la donne, pour que ces IA convoquent d’autres forces narratives, d’autres imaginaires, d’autres représentations. Les réponses des IA génératives sont sensibles aux contextes discursifs, aux représentations, aux images qui les font dévier. « Un modèle invité à se comporter comme un expert en oiseaux décrit les oiseaux plus précisément qu’un autre invité à se comporter comme un expert en voiture ». Les LLM sont finalement extrêmement sensibles aux imaginaires qu’on convoque”.
[13] Les fameux token ou jetons ou unité de sens, mais qui sont avant tout des identifiants numériques uniques qui traduisent les mots en suite de chiffres qui permettent de créer des relations statistiques entre ces suites de chiffres et entre les groupes de mots entre eux. Pour bien comprendre la tokenisation, le mieux est de la tester, par exemple avec l’outil que propose ChatGpt : https://platform.openai.com/tokenizer Voir les explications de Hugo Bernard, “C’est quoi un « token » ou « jeton » quand on parle d’intelligence artificielle générative ?”, Numerama, 16 février 2025 : https://www.numerama.com/tech/1902803-cest-quoi-un-token-quand-on-parle-dintelligence-artificielle-generative.html et surtout celles de Thomas Mahier, “C'est quoi un modèle de langage (ChatGPT, Claude, Mistral..) ? Explications : du token à l'escargot”, Flint Media, 14 octobre 2023 : https://generationia.flint.media/p/secrets-techniques-chatgpt-bard-claude
[14] Des réglages que le juriste Jonathan Zittrain invitait à ouvrir via des bases partagées. Si un chatbot ne dit rien de ce qu’il s’est passé sur la place Tiananmen en 1989, nous devons pouvoir comprendre pourquoi, défendait-il. « Ceux qui construisent des modèles ne peuvent pas être les arbitres silencieux de la vérité des modèles. » Jonathan Zittrain, “The Words That Stop ChatGPT in Its Tracks”, The Atlantic, 17 décembre 2024 : https://www.theatlantic.com/technology/archive/2024/12/chatgpt-wont-say-my-name/681028/ Voir aussi, Hubert Guillaud, “Comment les IA sont-elles corrigées ?”, Danslesalgorithmes.net, 16 décembre 2024 : https://danslesalgorithmes.net/stream/comment-les-ia-sont-elles-corrigees/ Voir aussi par exemple les travaux de la chercheuse Ksenia Ermoshina sur la construction des filtres et de la censure dans les IA génératives qui montre que celles-ci sont souvent extrêmement rudimentaires, sous formes de simples listes de mots, même dans les grands modèles de langage : https://cis.cnrs.fr/ksenia-ermoshina
[15] “AI poses no existential threat to humanity – new study finds”, Bath University, 12 août 2024 : https://www.bath.ac.uk/announcements/ai-poses-no-existential-threat-to-humanity-new-study-finds/ Will Douglas Heaven, “How AGI became the most consequential conspiracy theory of our time”, Technology Review, 30 octobre 2025 : https://www.technologyreview.com/2025/10/30/1127057/agi-conspiracy-theory-artifcial-general-intelligence/ et Hubert Guillaud, “Intelligence artificielle générale : le délire complotiste de la tech”, Danslesalgorithmes.net, 18 novembre 2025 : https://danslesalgorithmes.net/2025/11/18/intelligence-artificielle-generale-le-delire-complotiste-de-la-tech/
[16] Hubert Guillaud, “Qui est l’utilisateur des LLM ?”, Danslesalgorithmes.net, 10 juin 2025 : https://danslesalgorithmes.net/2025/06/10/qui-est-lutilisateur-des-llm/
[17] Voir par exemple les outils que développe le laboratoire Pair de Google : https://pair.withgoogle.com ou encore le GemmaScope qui permet d’éclairer le fonctionnement des modèles Gemma de Google : https://www.neuronpedia.org/gemma-scope#main
[18] “La grande disponibilité des données et des possibilités de calculs nous font oublier que l’opacité et la complexité qu’ils génèrent produisent des améliorations marginales par rapport au problème démocratique que posent cette opacité et cette complexité. Nous n’avons pas besoin de meilleurs calculs – que leur complexification ne produit pas toujours –, que de calculs capables d’être redevables”. Arvind Narayanan et Sayash Kapoor, AI Snake Oil (Princeton University Press, 2024, non traduit). Hubert Guillaud, “Comprendre ce que l’IA sait faire et ce qu’elle ne peut pas faire”, Danslesalgorithmes.net, 19 octobre 2024 : https://danslesalgorithmes.net/2024/10/10/comprendre-ce-que-lia-sait-faire-et-ce-quelle-ne-peut-pas-faire/
|
📆Agenda et actualités de Café IA |
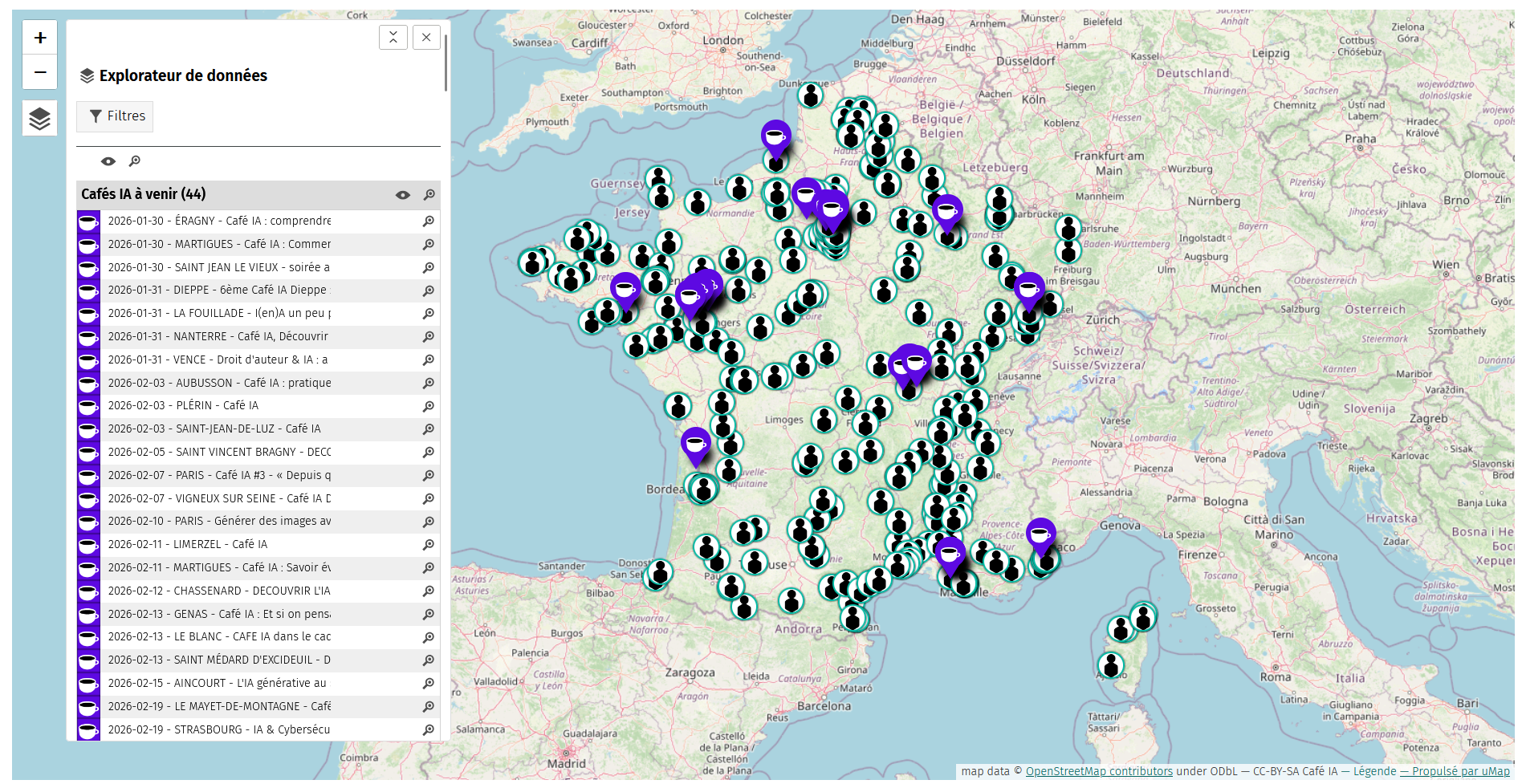
🗺️La carte interactive est en ligne !
|
Comme annoncé depuis plusieurs semaines, la carte interactive Café IA est désormais en ligne et nous en sommes très heureux. Conçue comme un outil ouvert et collaboratif, elle permet de découvrir les Cafés IA déjà actifs, d’identifier les animateur·rices sur chaque territoire et de donner de la visibilité aux initiatives en cours de création. Elle s’adresse aussi bien aux personnes curieuses qu’aux participant·es, animateur·rices ou porteur·ses de projet, et facilite les rencontres et les dynamiques locales autour des Cafés IA.
Si vous animez déjà un Café IA ou si vous envisagez d’en créer un, vous pouvez le référencer directement sur notre formulaire dédié. |
|
|
Les Cafés IA de cette semaine. Participez ! -
Le 31 janvier, à Vence, la médiathèque organise une session dédiée au Droit d'auteur & IA : A qui appartiennent nos imaginaires ?
-
Le 31 janvier, à Dieppe, un 6ème Café IA proposera une Prompt Battle
-
Le 31 janvier à Nanterre, le centre social et culturel Parc en Ciel organise le premier Café IA de la ville pour découvrir et tester différentes intelligences artificielles.
- Le 31 janvier à La Fouillade, un atelier Café IA proposera de s’intéresser aux IA illustratrices à travers jeux et expérimentations.
-
Les 2 et 4 février à Ajaccio, Parlemu IA propose un Café IA à Avvià, A vela, Port de Toga.
- Le 3 février à Saint-Jean-de-Luz, rendez-vous à la médiathèque pour échanger autour de l’IA dans une ambiance conviviale.
- Le 3 février à Aubusson, un Café IA permettra d’expérimenter les plateformes d’IA pour optimiser ses écrits, ses recherches et découvrir l’aide à la création d’images.
-
Le 3 février à Plérin, un Café IA invite à discuter simplement de l’intelligence artificielle lors d’un café numérique à l’espace partage.
- Le 5 février à Argentan, le Café IA Prompteurs et prompteuses.
-
Le 5 février à Saint-Vincent-Bragny, un Café IA Découvrir l’IA est proposé pour aborder les usages et enjeux de l’intelligence artificielle.
-
Le 7 février à Paris, au Carrefour numérique² de la Cité des sciences et de l’industrie, un Café IA reviendra sur l’histoire de l’intelligence artificielle dans le jeu vidéo et questionnera ses usages, promesses et limites.
-
Le 7 février à Vigneux-sur-Seine, un Café IA Découverte invite le public à venir découvrir l’avenir à l’aide de l’IA.
Du côté de nos partenaires, retrouvez :
- les Cafés IA PME-TPE France Num par ici ;
-
et les Cafés IA à destination des enseignants comme du grand public du Réseau Canopé par là.
|
🎇 Venez rencontrer l’équipe de Café IA |
Les 4 et 5 février, l'équipe Café IA sera au salon Tech&Fest à Grenoble. Découvrez notre programme !
Venez échanger avec l'équipe et nos partenaires: Association Latitudes, Réseau Canopé sur l'événement ! Nous disposons d'invitations. |
🎨Les Cafés animation à venir !
|
Vous souhaitez animer un Café IA ou partager votre expérience ? Participez aux prochains cafés animations en ligne, le jeudi de 13h30 à 15h pour découvrir des formats d’animation, des ressources pédagogiques sur l’IA et faire part de vos retours d’expérience. Un moment convivial pour s’inspirer et apprendre ensemble ! |
- Pas de Café Animation le jeudi 5 février
-
Jeudi 12 février : Café Animation pour les Activateurs France Num et Ambassadeurs Osez l'IA : Présentation de la Semaine de l'IA pour Tous à destination des PME - TPE. La Semaine de l’IA pour Tous aura lieu du 18 au 24 mai 2025. Comment associer vos événements au programme ? Comment participer ? Café IA, la MEDNUM et FRANCE NUM répondront à toutes les questions que vous vous posez.
|
✨ 18-24 mai : la semaine de l’IA pour tous |
On lance le collectif de La Semaine de l'IA pour Tous ! Rejoignez le mouvement !
Nous sommes ravis de vous convier à nos 2 prochains webinaires de présentation de La Semaine de l’IA pour Tous, qui se tiendra du 18 au 24 mai 2026 dans toute la France, un événement mis en place avec la MEDNUM et Make.org.
Cet événement a une ambition : sensibiliser 50 000 citoyens aux enjeux et usages de l’intelligence artificielle, en organisant plus de 1 500 évènements sur tout le territoire grâce à toutes les structures qui souhaiteraient se mobiliser avec nous. |
|
|
💥 La ressource de la semaine |
Sur la plateforme France université numérique on trouve plusieurs cours en ligne sur l’intelligence artificielle. Notamment celui proposé par l’Université Grenoble Alpes sur l’IA et la société. Accessible gratuitement, sur inscription, se déroulant sur 5 semaines entre mars et avril, le cours propose de faire un point, en 8 heures, sur les enjeux sociaux de l’IA.
On en trouve bien d’autres encore en ligne. Par exemple, Les éléments de l’IA proposés par l’université d’Helsinki, en français. Sur OpenClassrooms, on trouve un cours d’initiation à l’IA en 6 heures. Sur la plateforme Edx, l’université de Montréal propose également quelques initiations sur le sujet (payantes).
Vous trouverez également beaucoup de propositions sur le sujet sur la plateforme Coursera où les premiers cours sont parfois offerts, comme ceux proposés par Google. Et notamment le plus célèbre d’entre eux, celui d’Andrew Ng : l’IA pour tous (payant).
La plupart des plateformes d’IA proposent également des cours pour découvrir leurs outils et apprendre à les maîtriser, comme Anthropic Academy ou OpenAI academy. Voir de la documentation, des espaces d’échanges ou des tutoriels pour se lancer, comme le propose Mistral. Microsoft et Simplon s’y mettent également ainsi que France Travail.
Si vous en avez découvert ou testé d’autres, n’hésitez pas à nous les signaler sur bonjour@cafeia.org !
|
Merci de nous avoir lus ! Si vous avez apprécié la lettre d’information de cette semaine, partagez-la ! Tout à chacun peut s’inscrire ici. Comme d’habitude, n’hésitez pas à nous faire vos retours. Vous avez des questions, des remarques ou des suggestions ou vous souhaitez que nous abordions un sujet en particulier ? Nous sommes à votre écoute ! N’hésitez pas à répondre à ce mail ou à nous écrire à bonjour@cafeia.org. |
|
|
|